哈希
About Hash
哈希是密码学的基础,理解哈希是理解数字签名和加密通信等技术的必要前提
哈希,英文是 hash ,本来意思是”切碎并搅拌“,有一种食物就叫 Hash ,就是把食材切碎并搅拌一下做成的。哈希函数的运算结果就是哈希值,通常简称为哈希。哈希函数有时候也翻译做散列函数
原文出处: https://blog.csdn.net/xuhao885544/article/details/84751135
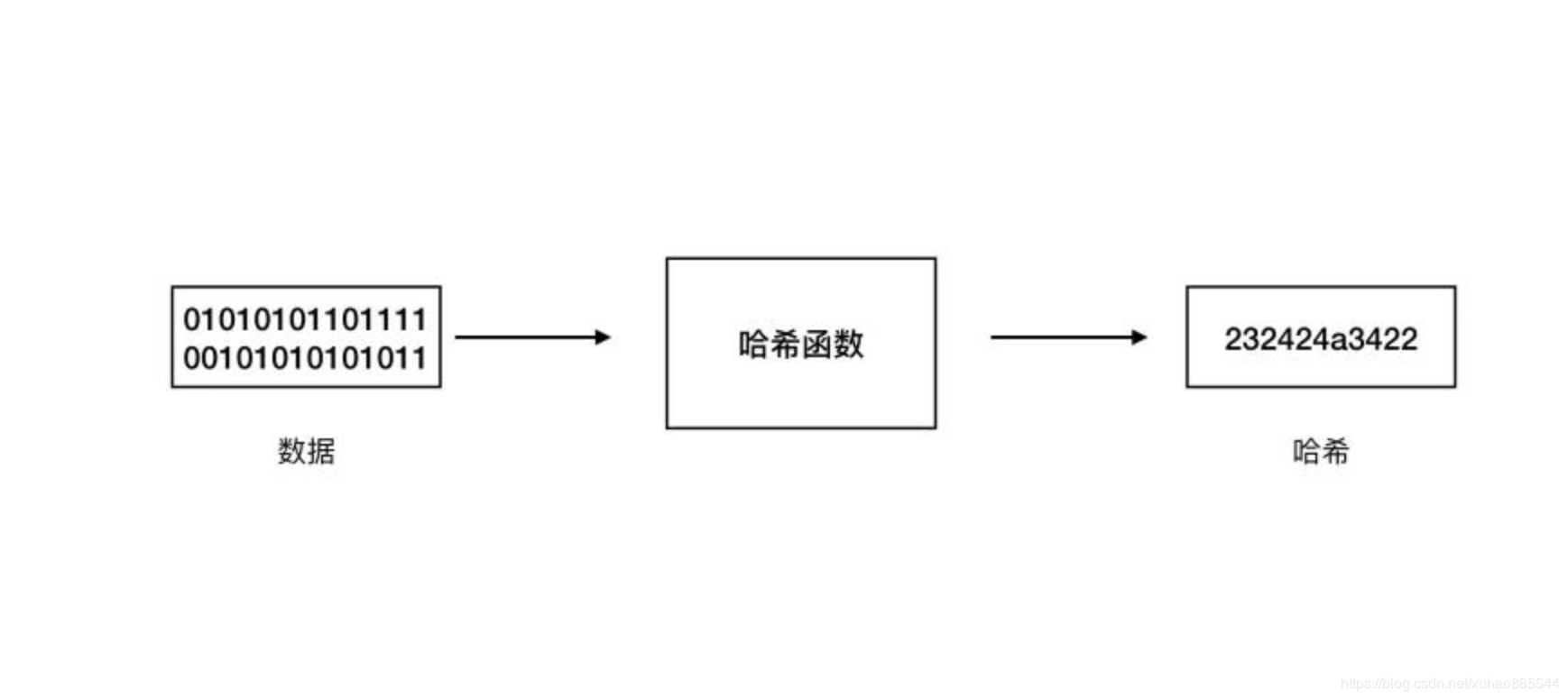
The Job of Hash
给一个任意大小的数据生成出一个固定长度的数据,作为它的映射
The Features of Hash
- 单向算法,给定数据 M 容易算出哈希值 X ,而给定 X 不能算出 M.(保证了安全问题)
- 独一无二,两个不同的数据,拥有不相同的哈希
- 长度固定,给定一种哈希算法,不管输入是多大的数据,输出长度都是固定的。
Collision
由于哈希的长度是固定的,所以(输出)值域有限,而(输入)定义域无限,终会出现不同数据有相同哈希的情况,称为碰撞(collision)。
不同的哈希算法,哈希位数越多,也就基本意味着安全级别越高,或者说它的”抗碰撞性“就越好。
The Function of Hash
哈希的独一无二性,保证了如果数据在存储或者传输过程中有丝毫损坏,那么它的哈希就会变。哈希函数的最常见的一个作用就是进行完整性校验( Integrity Check ),完整的意思是数据无损坏
Application example
网站注册:
当我们提交用户名密码的时候,用户名被会直接保存到网站的数据库中,但是密码却不是直接保存的,而是先把密码转换成哈希,保存到数据库中的其实是哈希。
所以,即使是公司后台管理人员,也拿不到用户的密码。这样,如果万一公司数据库泄露了,用户的密码依然是安全的。
而当用户自己登录网站的时候,输入密码提交到服务器,服务器上进行相同的哈希运算,因为输入数据没变,所以哈希也不会变,登录也就成功了
以下开启我的理解
a * x = b * y
输入a与b,x、y为某区间(假设为[1, 100])内的整数,求共有多少方案满足上述等式
普通做法
int ans = 0;
for(int x = 1; x <= 100; ++x)
for(int y = 1; y <= 100; ++y)
if(a * x == b * y)
ans++;
复杂度O(n * n)
思考过程,会发现:
当x = 1时,我们用了O(n)的时间计算了每一个b * y(针对y的所有可能值),然后去跟a * x比较是否相等
然而,x = 2时,我们又用了O(n)的时间计算了每一个b * y
就这样,x = 3, 4, 5 …100时,我们做了n次重复计算,每次时间O(n),就有了O(n * n)的时间复杂度
那么我们想着:第一次循环就记录下所有值,复杂度岂不降为O(n)?
于是就有了
哈希
哈希数组
我们将枚举时的自变量(原象)作为哈希数组的下标,因变量(投影)作为哈希数组的储存值,这样可以将枚举过程的结果记录下来,省去了后续的重复枚举
局限
因为自变量(原象)作为下标,而下标是非负整数,所以题目枚举的自变量必须为有界整数,为了保证“非负”,有时需要坐标偏移
int ans = 0;
for(int i = 1; i <= 100; ++i)
has[b * i]++; //记录下所有的 b * y
for(int i = 1; i <= 100; ++i)
ans += has[a * i]; //统计方案数
最后一行代码, a * x 有相等的 b * y时,
has[a * i] = 1,方案数加一,否则has[a * i] = 0,方案数加零(不增)对于此题,hash数组可以为bool类型,不过对于大多数题目,同一结果可能有不同的方案,hash数组必须用int类型
总结Hash
记录过程值,以空间换时间