Python爬取SDNUOJ两用户Solved problems查找遗漏的水题
Description
输入用户名,爬取SDNUOJ指定用户Information页面Solved Problems题号,通过对比,输出对方已解决而自己尚未解决的题目的题号
可执行文件下载链接:https://github.com/fireworks99/Tools/raw/master/OJ_compare_sloved.exe
Thanks
感谢LTR师哥( https://blog.csdn.net/ltrbless )耐心指导,拿出自己珍贵的大把的时间悉心为我讲解细节,在我求“鱼”之时授我以“当下之鱼”及“来日之渔”
题目做腻了的时候看了看爬虫入门的东西,偶然想起某天MF(YMF https://solodance.top/ )与旁人闲聊时提到这个(爬取两用户Information比较得出自己遗漏的水题)有趣的东西,想着自己也试试。在此说明原Idea来自于他。
Code
import urllib.request
from bs4 import BeautifulSoup
fro = 'http://www.acmicpc.sdnu.edu.cn/user/info/'
print("Please input your Username:")
my_url = input()
my_url = fro + my_url
print("Please input his or her Username:")
its_url = input()
its_url = fro + its_url
# print(my_url)
# print(its_url)
my_res = ""
its_res = ""
# 获得html文档
try:
my_res = urllib.request.urlopen(my_url)
its_res = urllib.request.urlopen(its_url)
except Exception as e:
print(e)
if my_res is "":
print("Your Username is wrong")
elif its_res is "":
print("His or her Username is wrong")
else:
# print(my_res.getcode())
# print(its_res.getcode())
# 创建BeautifulSoup对象
my_bs = BeautifulSoup(my_res, features='html.parser', from_encoding='utf-8')
its_bs = BeautifulSoup(its_res, features='html.parser', from_encoding='utf-8')
# 找到所有 标签为"div",class_ 属性为"row"的内容,返回一个列表
my_list = my_bs.find_all("div", class_="row")
its_list = its_bs.find_all("div", class_="row")
# print(my_list[4]) # 共七个元素,我们发现第五个是我们想要的,它本身是一个标签(Tag)
# print(type(my_list))
# print(type(my_list[4]))
# 将该标签通过str强转为字符串作为文本,再次构建一个BeautifulSoup对象
# my_soup = BeautifulSoup(unicode(my_list[4]), features='html.parser') # py2 -> unicode / py3 -> str
my_soup = BeautifulSoup(str(my_list[4]), features='html.parser')
its_soup = BeautifulSoup(str(its_list[4]), features='html.parser')
# 在此范围内查找所有的'a'标签,即链接
my_soup = my_soup.find_all('a')
its_soup = its_soup.find_all('a')
# print(my_soup.find_all('a'))
# 用 .string 取出其中的NavigableString(可操纵字符串)对象,即已通过题目的题号,生成列表
my_sloved = []
for i in my_soup:
my_sloved.append(i.string)
its_sloved = []
for i in its_soup:
its_sloved.append(i.string)
for i in its_sloved:
if i not in my_sloved:
print(i)
else:
continue
print("No more!")
Process
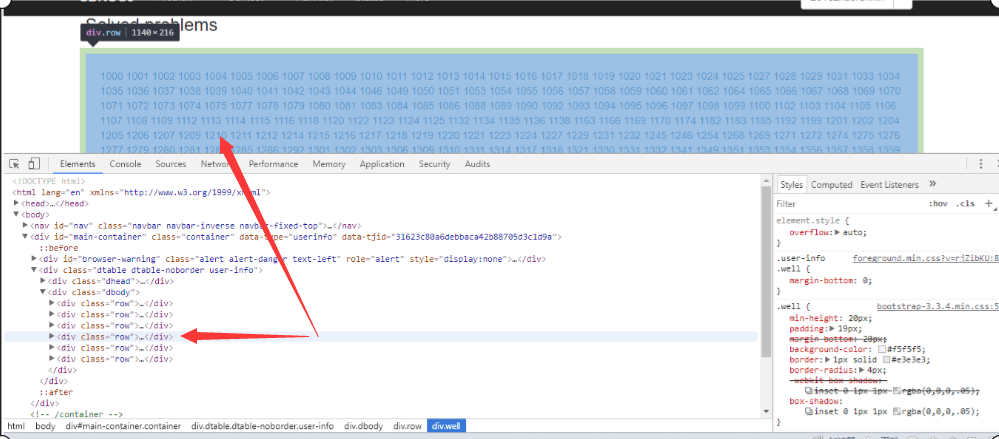
审查元素
鼠标指着某段代码会出现相应模块,我们当前指向即为所需部分(Solved Problems)
发现其Tag(标签)为”div”,class_属性为”row”
find_all所有这样的内容,返回一个my_list列表
其中第5个元素,即my_list[4]是我们想要的Solved模块,将其转为字符串文本,创建为一个新的BeautifulSoup对象
对新对象find_all(‘a’),标签a为“链接类”标签
<a href="/status/list?name=2018zhaobaole&pid=1025&type=10">1025</a>后面的1025属于NavigableString(可操纵字符串)对象,可以通过
.string直接访问不懂的语法、函数去官方文档(BeautifulSoup4.2.0文档)找
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
更多内容详见code
Attention
使用上述代码时需要保证该Python Project中有beautifulsoup4解释器
pycharm如何安装beautifulsoup4:https://blog.csdn.net/huatian5/article/details/74502687