Python网络爬虫与信息提取
Description
- request.get()
- 处理异常
- 通用框架
- 模拟浏览器访问
- 向搜索引擎提交关键词获取搜索结果
- 网络图片(视频、动画等二进制资源)的爬取与存储
- 大量图片的爬取与存储
- IP地址归属地的自动查询
一.request.get()
import requests
# 构造一个向服务器请求资源的Request对象,返回一个包含服务器资源的Response对象(即r)
r = requests.get("http://www.baidu.com")
# Response对象的五种属性
print(r.status_code )
print(r.encoding) # 猜测编码方式
print(r.apparent_encoding) # 分析编码方式
r.encoding = r.apparent_encoding
print(r.text)
print(r.content) # HTTP响应内容的二进制形式(还原图片等)
二.处理异常
import requests
# 爬取网页的通用代码框架
"""
网络连接有风险
处理异常很重要
"""
def getText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status() # 如果不是200, 引发HTMLError异常,跳到except
r.encoding = r.apparent_encoding # 这步好像挺耗时的
return r.text
except:
return "Error occurred"
if __name__ == "__main__":
url = "https://fireworks99.github.io/"
print(getText(url))
三.通用代码框架
import requests
# 爬取网页的通用代码框架
def getText(url):
try:
r = requests.get(url)
r.raise_for_status()
return "Succeed"
except:
return "Error occurred"
if __name__ == "__main__":
url = "https://fireworks99.github.io/"
print(getText(url))
r = requests.head(url) # 用较少的网络流量获取概要信息
print(r.headers)
print(r.text) # 空了
四.模拟浏览器访问
import requests
url = "https://www.amazon.cn/dp/B072Z88B9T/ref=zg_bs_116169071_2?_encoding=UTF8&psc=1&refRID=7S6CK24KSH7ARE601YXF"
r = requests.get(url)
print(r.status_code) # 503
"""
r.encoding = r.apparent_encoding
print(r.text)
# "出现错误" API造成
"""
"""
print(r.request.headers)
# {'User-Agent': 'python-requests/2.19.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
爬虫告诉亚马逊的服务器:此次访问是一个python的requests库的一个程序制造的(User-Agent)
那么亚马逊的服务器可以通过 来源审查 拒绝这样的访问
"""
"""
更改头部信息,模拟浏览器向网站发送请求
"""
kv = { 'user-agent': 'Mozilla/5.0' } # 标准浏览器身份标识字段
r = requests.get(url, headers = kv)
print(r.status_code) # 200
print(r.request.headers)
# {'user-agent': 'Mozilla/5.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
print(r.text)
五.提交关键词获取搜索结果
import requests
"""
向搜索引擎提交关键词并获取搜索结果
百度关键词接口:
http://www.baidu.com/s?wd=keyword
360关键词接口:
http://www.so.com/s?q=keyword
"""
keyword = "Python"
try:
kv = { 'wd':keyword }
r = requests.get("http://www.baidu.com/s", params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("Error occurred")
try:
kv = { 'q':keyword }
r = requests.get("http://www.so.com/s", params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("Error occurred")
六.网络图片的爬取与存储
import os
import requests
url = "https://www.lifeofpix.com/wp-content/uploads/2019/08/DJI_0452-1600x1057.jpg"
root = "E://pycharm//crawl//pictures//"
path = root + url.split('/')[-1] # url中以 '/' 分割的最后一部分
try:
if not os.path.exists(root): # 根目录是否存在,不存在就建立
os.mkdir(root)
if not os.path.exists(path): # 文件是否存在,不存在才去爬取
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)# 图片是以二进制形式保存的,恰好 r.content返回的也是二进制的内容
f.close()
print("Succeed")
else:
print("File already exists!")
except:
print("Crawl failed!")
七.网络图片批量爬取
import os
import requests
from bs4 import BeautifulSoup
def getText(url):
try:
kv = {'user-agent': 'Mozilla/5.0'}
r = requests.get(url, headers = kv) # 知乎有来源审查
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "Error"
if __name__ == "__main__":
url = "https://www.zhihu.com/question/63202062/answer/209514500"
r = getText(url)
bs_obj = BeautifulSoup(r, features='html.parser')
pic_list = bs_obj.find_all("img")
img_list = []
idx = 0
for link in pic_list:
idx += 1
if idx % 2 == 0: # 偶数项是我们需要的
img_list.append(link['src'])
else:
pass
root = "E://pycharm//crawl//pictures//"
try:
if not os.path.exists(root): # 根目录是否存在,不存在就建立
os.mkdir(root)
for url in img_list:
path = root + url.split('/')[-1] # url中以 '/' 分割的最后一部分
if not os.path.exists(path): # 文件是否存在,不存在才去爬取
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content) # 图片是以二进制形式保存的,恰好 r.content返回的也是二进制的内容
f.close()
else:
pass
except:
print("Crawl failed!")
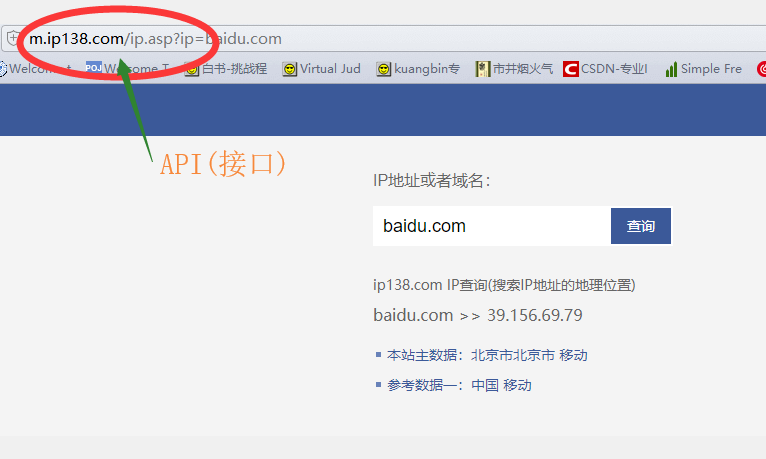
八.IP地址归属地的自动查询
import requests
url = "http://m.ip138.com/ip.asp?ip=" # API
address = input()
try:
kv = { 'user-agent': 'Mozilla/5.0' }
r = requests.get(url + address, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-500:]) # 约束范围空间,否则可能影响IDE的使用
except:
print("Error")