About BeautifulSoup
Description
- BeautifulSoup的基本元素
- HTML内容遍历方法
- HTML格式化
- 信息标记与内容查找方法
1.BeautifulSoup五种基本元素

import requests
from bs4 import BeautifulSoup
def getText(url):
try:
kv = { 'user-agent': 'Mozilla/5.0' }
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return 'Error'
def solve(txt):
soup = BeautifulSoup(txt, 'html.parser')
print(soup.title)
print(soup.a) # 标签(只返回了第一个标签内容)
print(type(soup.a)) # <class 'bs4.element.Tag'>
print(soup.a.name) # 标签名字
print(type(soup.a.name)) # <class 'str'>
print(soup.a.parent.name)
print(soup.a.parent.parent.name)
print(soup.a.attrs) # 标签属性
print(type(soup.a.attrs)) # <class 'dict'>
print(soup.a.attrs['href']) # 采用字典的方式提取信息
print(soup.a.string)
print(type(soup.a.string)) # <class 'bs4.element.NavigableString'>
newsoup = BeautifulSoup('<b><!--This is a comment--></b><p>This is not a comment</p>', 'html.parser')
print(newsoup.b.string) # This is a comment 自动去掉了注释标志
print(type(newsoup.b.string)) # <class 'bs4.element.Comment'>
print(newsoup.p.string) # This is not a comment
print(type(newsoup.p.string)) # <class 'bs4.element.NavigableString'>
def main():
url = "https://www.csdn.net/"
txt = getText(url)
solve(txt)
if __name__ == '__main__':
main()
2.HTML内容的三种遍历



Code
import requests
from bs4 import BeautifulSoup
def getText(url):
try:
kv = { 'user-agent': 'Mozilla/5.0' }
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return 'Error'
def down(demo):
soup = BeautifulSoup(demo, 'html.parser')
print(soup.head)
print(soup.head.contents) # head标签子节点(包括:标签节点、字符串节点(像'\n'))的列表
print(type(soup.head.contents)) # <class 'list'>
print(soup.body)
print(soup.body.contents)
print(len(soup.body.contents))
print(soup.body.contents[1])
for child in soup.body.children: # 循环遍历子节点(迭代类型只能用在for...in...结构中)
print(child)
for grandchild in soup.body.descendants: # 循环遍历所有子孙节点(迭代类型)
print(grandchild)
def up(demo):
soup = BeautifulSoup(demo, 'html.parser')
for parent in soup.a.parents: # 节点的"先辈"标签,没有则None
if parent is None:
print(parent)
else:
print(parent.name)
print(soup.title.parent) # 节点的父亲标签
print(soup.html.parent) # html为最高标签,父节点为自己
def parallel(demo):
soup = BeautifulSoup(demo, 'html.parser')
print(soup.a.next_sibling)
print(soup.a.next_sibling.next_sibling)
print(soup.a.previous_sibling)
print(soup.a.previous_sibling.previous_sibling)
print(soup.a.parent)
for sibling in soup.a.next_siblings: # 迭代类型,遍历后序节点
print(sibling)
for sibling in soup.a.previous_siblings: # 迭代类型,遍历前序节点
print(sibling)
def main():
url = "https://fireworks99.github.io/"
demo = getText(url)
# down(demo)
# up(demo)
parallel(demo)
if __name__ == '__main__':
main()
3.HTML格式化prettify
import requests
from bs4 import BeautifulSoup
# 爬取网页的通用代码框架
def getText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "Error occurred"
if __name__ == "__main__":
url = "https://fireworks99.github.io/"
demo = getText(url)
soup = BeautifulSoup(demo, 'html.parser')
print(soup.prettify())
print(soup.a.prettify())
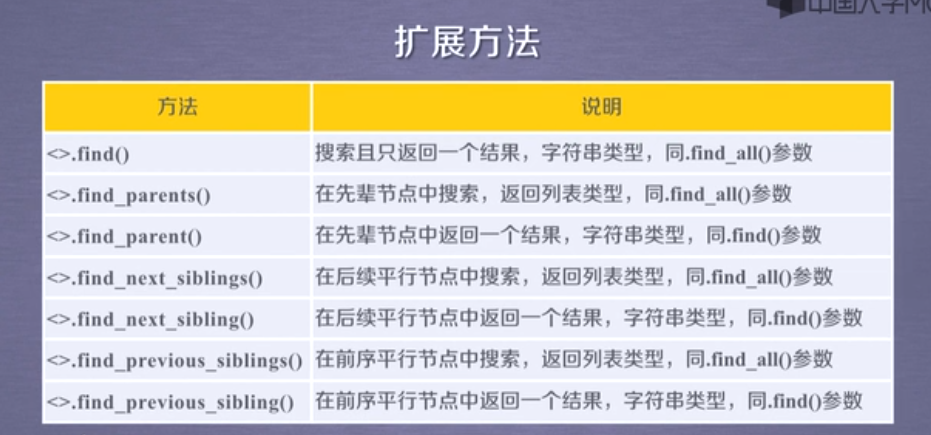
4.信息标记与内容查找方法